From Naive to Light: The Evolution of RAG Systems
What is RAG and how has it evolved? From Naive RAG to Advanced RAG to GraphRAG and LightRAG: understand the evolution of Retrieval-Augmented Generation systems. Retrieval-Augmented Generation (RAG) is a technique that combines information retrieval with LLM text generation, allowing AI systems to access external knowledge before generating responses. RAG has evolved from simple vector similarity search (Naive RAG) through query rewriting and re-ranking (Advanced RAG) to knowledge graph-based approaches (GraphRAG and LightRAG) that understand entity relationships. Components of an RAG System Refine Queries RAG HyDE based RAG Difference between various RAGs The key differences lie in how each system handles the external knowledge and the query: Advantages of LightRAG LightRAG Server UI Naive RAG uses simple vector similarity search to retrieve documents and passes them directly to the LLM. Advanced RAG adds pre-retrieval optimizations (query rewriting, HyDE), retrieval improvements (hybrid search, re-ranking) and post-retrieval processing (compression, filtering) to improve answer quality. GraphRAG builds a knowledge graph from your documents, extracting entities and relationships. Use it when your data has complex relationships between concepts (e.g., organizational hierarchies, medical knowledge bases) that flat vector search misses. It excels at multi-hop reasoning questions. LightRAG is a lightweight alternative to GraphRAG that builds a simpler knowledge graph with lower computational cost. It supports dual-level retrieval (low-level entity queries and high-level topic queries) and is easier to set up for smaller projects while still capturing entity relationships. Start with Naive RAG for simple Q&A over documents. Move to Advanced RAG when answer quality is insufficient (add re-ranking, query rewriting). Use GraphRAG/LightRAG when your questions require understanding relationships between entities or multi-hop reasoning across documents. Every RAG system has three core components: a retriever (finds relevant documents from your knowledge base), a context builder (formats retrieved documents for the LLM) and a generator (the LLM that produces the final answer using the retrieved context).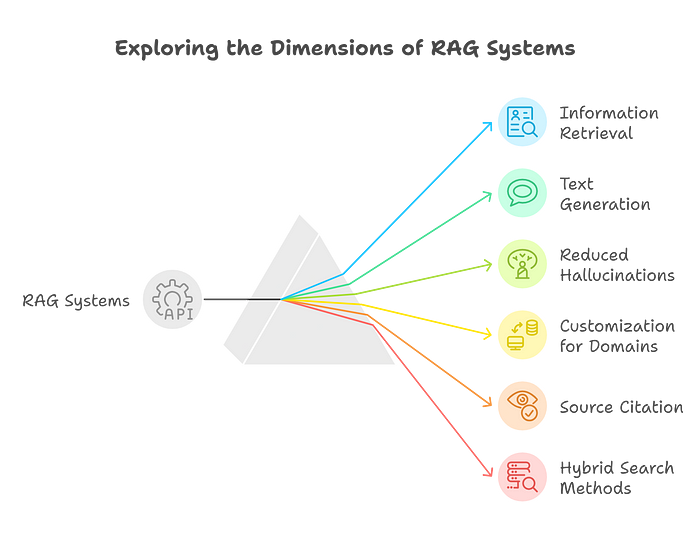
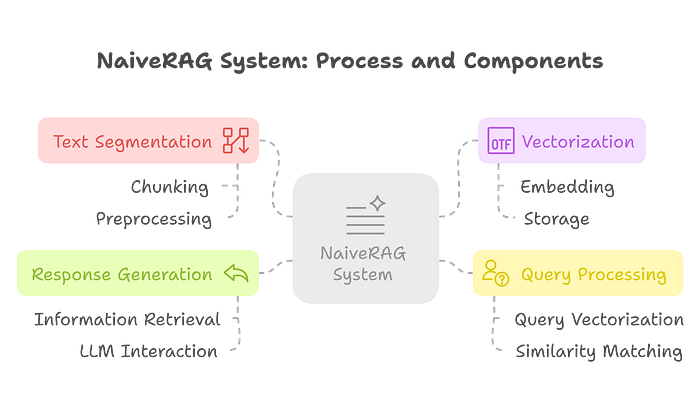
Naive RAG
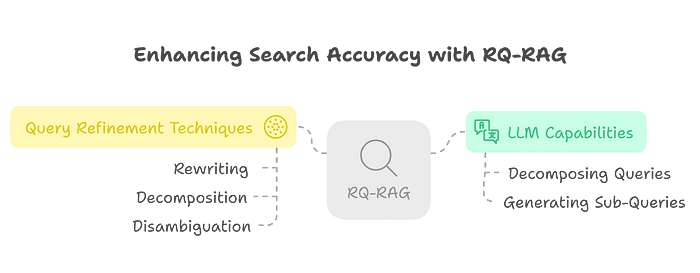
RQ-RAG
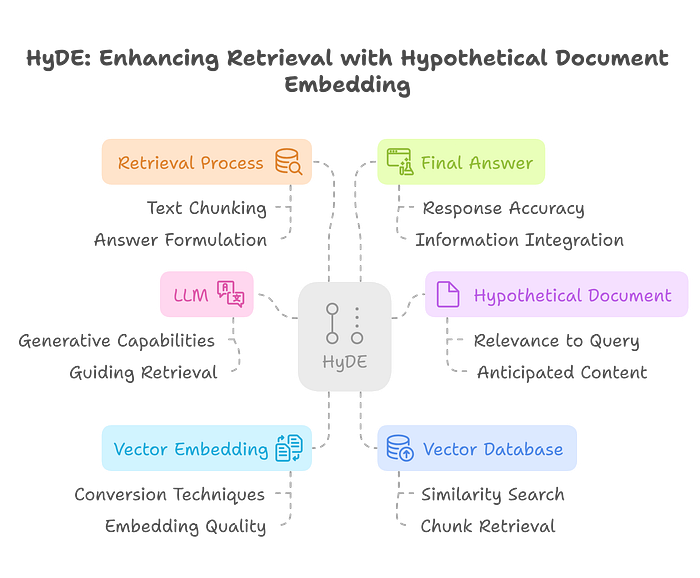
HyDE RAG
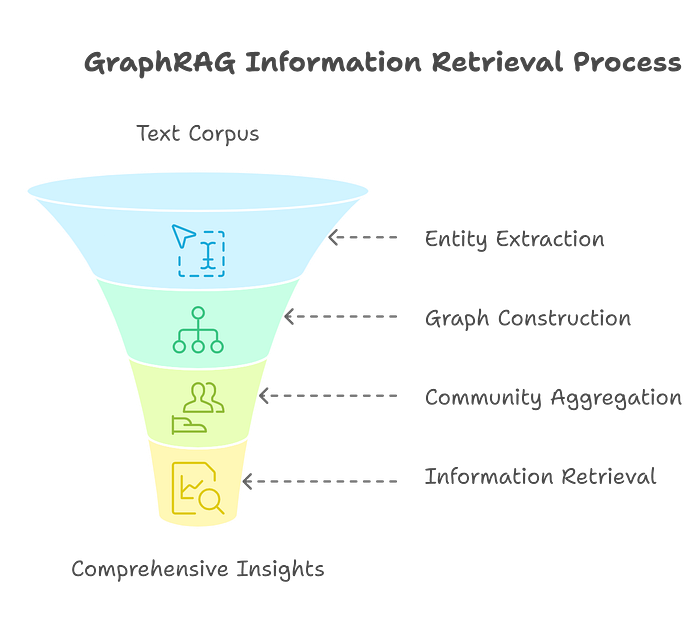
Graph RAG
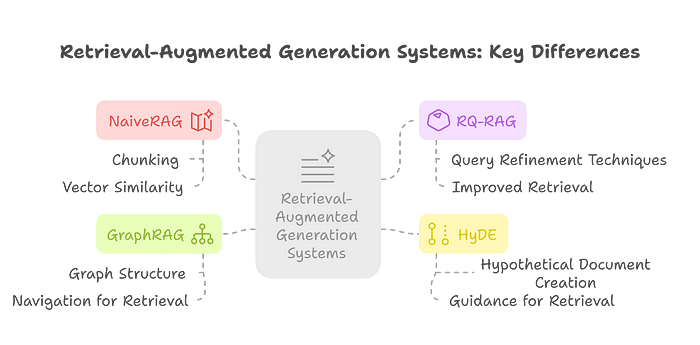
Summary
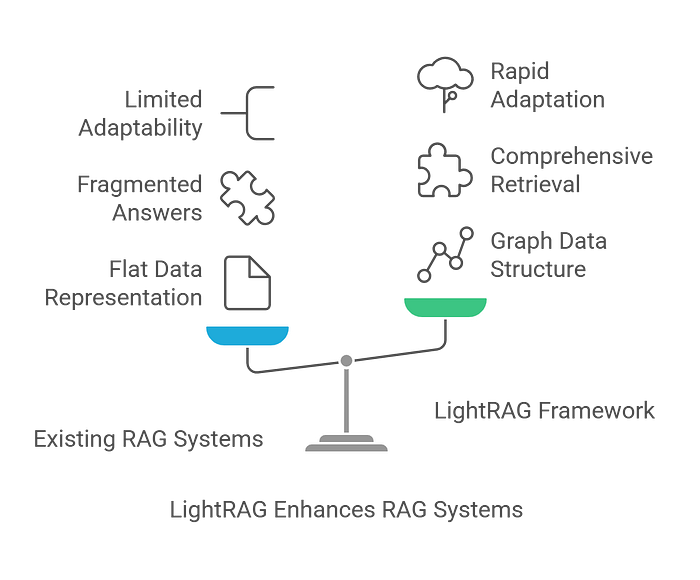
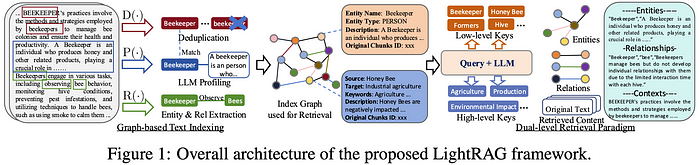
Enters LightRAG
import os
import asyncio
from lightrag import LightRAG, QueryParam
from lightrag.llm.openai import gpt_4o_mini_complete, gpt_4o_complete, openai_embed
from lightrag.kg.shared_storage import initialize_pipeline_status
from lightrag.utils import setup_logger
setup_logger("lightrag", level="INFO")
async def initialize_rag():
rag = LightRAG(
working_dir="data",
embedding_func=openai_embed,
llm_model_func=gpt_4o_mini_complete
)
await rag.initialize_storages()
await initialize_pipeline_status()
return rag
def main():
# Initialize RAG instance
rag = asyncio.run(initialize_rag())
# Insert text
rag.insert("Your text")
# Perform naive search
mode="naive"
# Perform local search
mode="local"
# Perform global search
mode="global"
# Perform hybrid search
mode="hybrid"
# Mix mode Integrates knowledge graph and vector retrieval.
mode="mix"
rag.query(
"What are the top themes in this story?",
param=QueryParam(mode=mode)
)
if __name__ == "__main__":
main()
Further Read
Frequently Asked Questions
What is the difference between Naive RAG and Advanced RAG?
What is GraphRAG and when should I use it?
What is LightRAG and how does it compare to GraphRAG?
How do I choose the right RAG approach for my project?
What are the main components of a RAG system?